[1] 2 4 6 8 10[1] "weight" "height" "gender"[1] TRUE TRUE FALSE[1] male male female
Levels: female maleR evolved from the S language, which was first developed by Rick Becker, John Chambers and Allan Wilks. S was created with the following goals in mind:
Later on, S evolved into S-PLUS, which then became rather costly. Ross Ihaka and Robert Gentleman from the University of Auckland decided to write a stripped-down version of S. They named the new language R. Five years later, version 1.0.0 of R was released on 29 Feb 2000. As of Dec 2025, the latest version of R is 4.5.2 It is maintained by the (R Core Team 2025).
To download R, go to CRAN, the Comprehensive R Archive Network, download the version for your operating system and install it.
A new major version is released once a year, and there are 2 - 3 minor releases each year. Upgrading is painful, but it gets worse if you wait to upgrade.
For our class, please ensure that you have version 4.5.1 or later. Functions in older versions work differently, so you might face problems or differences with some of the codes in the notes.
After installing, you can start using R straightaway. However, the basic GUI is not very user-friendly, as you can see from Figure 1.1. Instead of using the basic GUI for R, we are going to use RStudio. RStudio is an Integrated Development Environment (IDE) for R. It provides several features that base R does not, including:
The installation file for RStudio can be obtained from this URL. It is updated a couple of times a year. Make sure you have at least version 2025.09.x for our course.
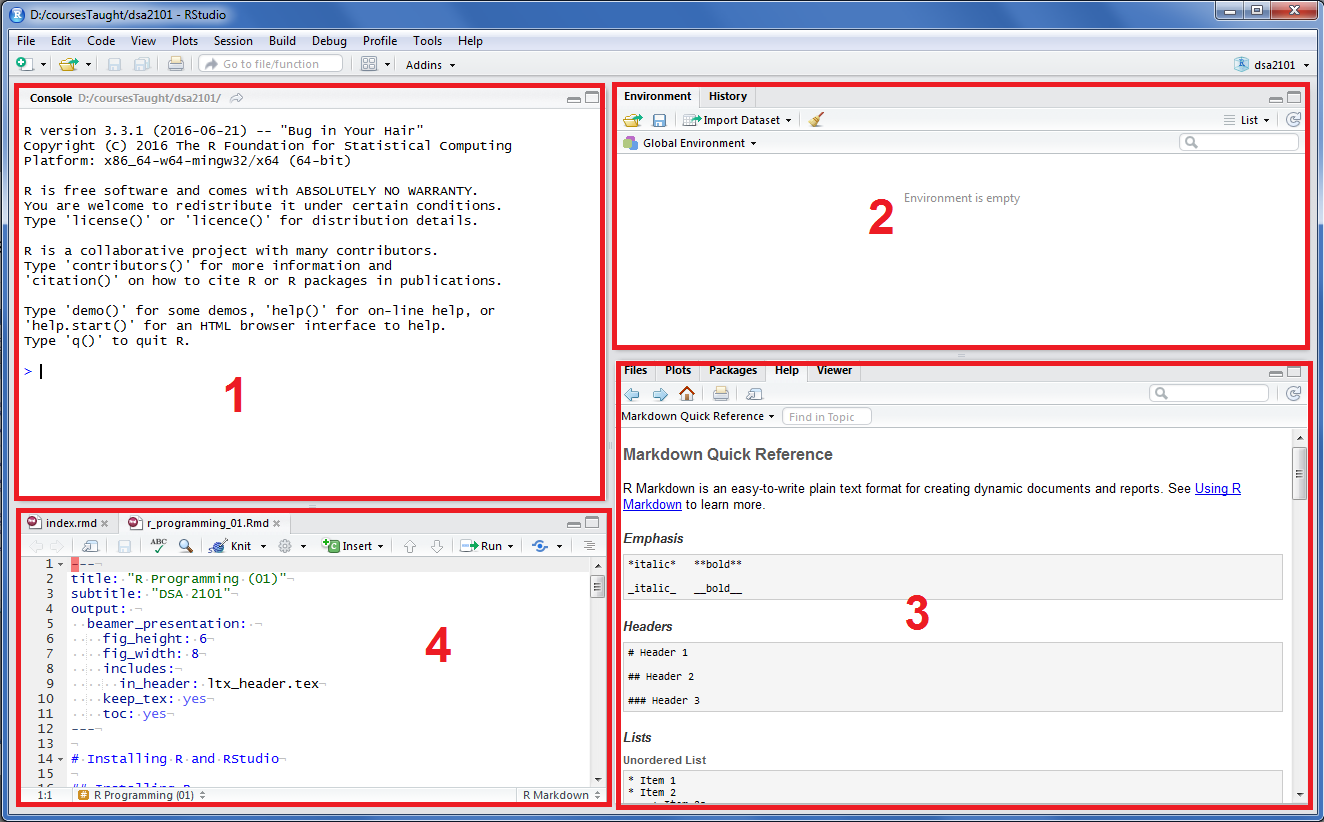
Here’s a quick orientation of the panels in Rstudio, with reference to Figure 1.2.
Probably the four most frequently used data structures in R are the following:
To create a vector in R, the simplest way is to use the combine function c().
[1] 2 4 6 8 10[1] "weight" "height" "gender"[1] TRUE TRUE FALSE[1] male male female
Levels: female maleFactors are slightly different from strings. In R, they are used to represent categorical variables in linear models.
When we need to create a vector that defines groups (of Females followed by Males, for instance), we can turn to a convenient function called rep(). This function replicates elements of vectors and lists. The syntax is as follows: rep(a, b) will replicate the item a, b times. Here are some examples:
[1] 2 2 2[1] 1 2 1 2 1 2[1] 6 6 3 3 3 3[1] "weight" "height" "gender" "weight" "height" "gender"On other occasions, we may need to create an index vector, along the rows of a dataset. The seq() function is useful for this purpose. It creates a sequence of numbers that are evenly spread out.
[1] 2 4 6 8 10[1] 2 4 6 8 10[1] 2.0 2.8 3.6 4.4[1] 4.0 5.6 7.2 8.8The final example above, where the sequence vector of length 4 is multiplied by a scalar 2, is an example of the recycling rule in R – the shorter vector is recycled to match the length of the longer one. This rule applies within all built-in R functions. Try to use this rule to your advantage when using R.
If you only need to create a vector of integers that increase by 1, you do not even need seq(). The : colon operator will handle the task.
Thus far, we have been creating vectors. Matrices are higher dimensional objects. To create a matrix, we use the matrix() function. The syntax is as follows: matrix(v,r,c) will take the values from vector v and create a matrix with r rows and c columns. R is column-major, which means that, by default, the matrix is filled column-by-column, not row-by-row.
[,1] [,2] [,3]
[1,] 1 3 5
[2,] 2 4 6 [,1] [,2] [,3]
[1,] 1 2 3
[2,] 4 5 6New rows (or columns) can be added to an existing matrix using the command rbind() (resp. cbind()).
Now let’s turn to dataframes, which are the most common object we are going to use for storing data in R. A dataframe is a tabular object, like a matrix, but the columns can be of different types; some can be numeric and some can be character, for instance. Think of a dataframe as an object with rows and columns:
As a general guideline, we should try to store our data in a format where a single variable is not spread across columns.
Example 1.1 (Tidy Data) Consider an experiment where there are three treatments (control, pre-heated and pre-chilled), and two measurements per treatment. The response variable is store in the following dataframe:
| Control | Pre_heated | Pre_chilled |
|---|---|---|
| 6.1 | 6.3 | 7.1 |
| 5.9 | 6.2 | 8.2 |
The above format is probably convenient for recording data. However, the response variable has been spread across three columns. The tidy version of the dataset is:
| Response | Treatment |
|---|---|
| 6.1 | control |
| 5.9 | control |
| 6.3 | pre_heated |
| 6.2 | pre_heated |
| 7.1 | pre_chilled |
| 8.2 | pre_chilled |
The second version is more amenable to computing conditional summaries, making plots and for modeling in R.
Dataframes can be created from matrices, and they can also be created from individual vectors. The function as.data.frame() converts a matrix into a dataframe, with generic column names assigned.
If we intend to pack individual vectors into a dataframe, we use the function data.frame(). We can also specify custom column names when we call this function.
Finally, we turn to lists. You can think of a list in R as a very general basket of objects. The objects do not have to be of the same type or length. The objects can be lists themselves. Lists are created using the list( ) function; elements within a list are accessed using the $ notation, or by using the names of the elements in the list.
$A
[1] 1 3 5
$B
[1] 1.000000 2.333333 3.666667 5.000000[1] 1.000000 2.333333 3.666667 5.000000[1] 1.000000 2.333333 3.666667 5.000000[1] 1 3 5Example 1.2 (Extracting \(p\)-values) The iris dataset is a very famous dataset that comes with R. It contains measurements on the flowers of three different species. Let us conduct a 2-sample \(t\)-test, and extract the \(p\)-value.
List of 10
$ statistic : Named num -15.4
..- attr(*, "names")= chr "t"
$ parameter : Named num 76.5
..- attr(*, "names")= chr "df"
$ p.value : num 3.97e-25
$ conf.int : num [1:2] -1.79 -1.38
..- attr(*, "conf.level")= num 0.95
$ estimate : Named num [1:2] 5.01 6.59
..- attr(*, "names")= chr [1:2] "mean of x" "mean of y"
$ null.value : Named num 0
..- attr(*, "names")= chr "difference in means"
$ stderr : num 0.103
$ alternative: chr "two.sided"
$ method : chr "Welch Two Sample t-test"
$ data.name : chr "setosa and virginica"
- attr(*, "class")= chr "htest"str( ) prints the structure of an R object. From the output above, we can tell that the output object is a list with 10 elements. The particular element we need to extract is p.value.
It is uncommon that we will be creating dataframes by hand, as we have been doing so far. It is more likely that we will be reading in a dataset from a file in order to perform analysis on it. Thus, at this point, let’s sidetrack a little and discuss how we can read data into R as a dataframe.
The two most common functions for this purpose are read.table() and read.csv(). The former is used when our data is contained in a text file, with spaces or tabs separating columns. The latter function is for reading in files with comma-separated-values. If our data is stored as a text file, it is always a good idea to open it and inspect it before getting R to read it in. Text files can be opened with any text editor; csv files can also be opened by Microsoft Excel. When we do so, we should look out for a few things:
The file crab.txt contains measurements on crabs. If you open up the file outside of R, you should observe that the first line of the file contains column names. By the way, head() is a convenient function for inspecting the first few rows of a dataframe. There is a similar function tail() for inspecting the last few rows.
V1 V2 V3 V4 V5
1 color spine width satell weight
2 3 3 28.3 8 3.050
3 4 3 22.5 0 1.550
4 2 1 26.0 9 2.300
5 4 3 24.8 0 2.100
6 4 3 26.0 4 2.600The data has not been read in correctly. To fix this, we need to inform R that the first row functions as the column names/headings.
color spine width satell weight
1 3 3 28.3 8 3.05
2 4 3 22.5 0 1.55
3 2 1 26.0 9 2.30
4 4 3 24.8 0 2.10
5 4 3 26.0 4 2.60
6 3 3 23.8 0 2.10If the first line of the data file does not contain the names of the variables, we can create a vector beforehand to store and then use the names.
Subject Gender CA1 CA2 HW
1 10 M 80 84 A
2 7 M 85 89 A
3 4 F 90 86 B
4 20 M 82 85 B
5 25 F 94 94 A
6 14 F 88 84 CThe use of read.csv() is very similar, but it is applicable when the fields within each line of the input file are separated by commas instead of tabs or spaces.
We now turn to the task of accessing a subset of rows and/or columns of a dataframe. The notation uses rectangular brackets, along with a comma inside these brackets to demarcate the row and column specifiers.
To access all rows from a particular set of columns, we leave the row column specification empty.
To retrieve a subset of rows, we use the space before the comma.
In R, dataframes are special kinds of lists. Hence, individual columns can be retrieved from a dataframe (as a vector) using the $ operator. These columns can then be used to retrieve only the rows that satisfy certain conditions. In order to achieve this task, we turn to logical vectors. The following code returns only the rows corresponding to Gender equal to “M”.
Logical vectors contain TRUE/FALSE values in their components. These vectors can be combined with & (AND) and | (OR) operations to yield only the rows that satisfy all conditions. Below, we return all rows where Gender is equal to “M” and CA2 is greater than 85.
For your reference , the table below contains all the logical operators in R.
| Operator | Description |
|---|---|
< |
less than |
> |
greater than |
<= |
less than or equal to |
>= |
greater than or equal to |
== |
equal to |
!= |
not equal to |
x | y |
(vectorised) OR |
x & y |
(vectorised) AND |
The $ operator is both a getter and a setter, which means we can also use it to add new columns to the dataframe. The following command creates a new column named id, that contains a running sequence of integers beginning from 1; the new column essentially contains row numbers.
Before we leave this section on dataframes, we shall touch on how we can rearrange the dataframe according to particular columns in either ascending or descending order.
Subject Gender CA1 CA2 HW id
1 10 M 80 84 A 1
4 20 M 82 85 B 4
2 7 M 85 89 A 2
6 14 F 88 84 C 6
3 4 F 90 86 B 3
5 25 F 94 94 A 5 Subject Gender CA1 CA2 HW id
5 25 F 94 94 A 5
3 4 F 90 86 B 3
6 14 F 88 84 C 6
2 7 M 85 89 A 2
4 20 M 82 85 B 4
1 10 M 80 84 A 1while loops execute a set of instructions as long as a particular condition holds true. On the other hand, for loops iterate over a set of items, executing the instructions a fixed number of times.
The syntax for a while loop is as follows. The condition is checked at the beginning of each iteration. As long as it is TRUE, the block of R expressions within the curly braces will be executed.
Here is an example of a while loop that increments a value until it reaches 10.
The general syntax for a for loop is as follows:
The “set” can be a sequence generated by the colon operator, or it can be any vector. Here is the same code from the while loop. Notice that x does not have to be initialised.
As a second example, consider these lines of R code, which prints out all squares of integers from 1 to 5. The cat( ) function concatenates a given sequence of strings and prints them to the console. We shall see more of it in Section 1.8.
The cat() function can be used to print informative statements as our loop is running. This can be very helpful in debugging our code. It works by simply joining any strings given to it, and then printing them out to the console. The argument "\n" instructs R to print a newline character after the strings.
When we are running a job in the background, we may want the output to print to a file so that we can inspect it later at our convenience. That is where the sink() function comes in.
When we have finished working with a dataframe, we may want save it to a file. For this purpose, we can use the following code. Once executed, the dataframe data2 will be written to a csv file named ex_1_with_IQ.csv in the data/ directory.
We have already seen several useful functions in R, e.g. read.csv and head. Here is a list of other commonly used functions.
| Function | Description |
|---|---|
max(x) |
Maximum value of x |
min(x) |
Minimum value of x |
sum(x) |
Total of all the values in x |
mean(x) |
Arithmetic average values in x |
median(x) |
Median value of x |
range(x) |
Vector of length 2: min(x), max(x) |
var(x) |
Sample variance of x |
cor(x, y) |
Correlation between vectors x and y |
sort(x) |
Sorted version of x |
R is a fully-fledged programming language, so it is also possible to write our own functions in R. To define a function for later use in R, the syntax is as follows:
The final line of the function definition will determine what gets returned when the function is executed. Here is an example of a function that computes the circumference of a circle of given radius.
All functions in R are documented. When you need to find out more about the arguments of a function, or if you need examples of code that is guaranteed to work, then do look up the help page (even before turning to stackexchange). The help pages within R are accessible even if you are offline.
To access the help page for a particular function, use the following command:
If you are not sure about the name of the function, you can use the following fuzzy search operator to return a page with a list of matching functions:
R is an open-source software. Many researchers and inventors of new statistical methodologies contribute to the software through packages1. At last check (Dec 2025), there are 23067 such packages. The packages can be perused by name, through this link.
To install one of these packages, you can use install.packages(). For instance, the following command will install stringr (a package for string manipulations) and all its dependencies on your machine.
Once the installation is complete, we still need to load the package whenever we wish to use the functions within it. This is done with the library() function:
To access a list of all available functions from a package, use:
In our course, we will only be using basic R syntax, functions and plots. You may have heard of the tidyverse set of packages, which are a suite of packages that implement a particular paradigm of data manipulation and plotting. You can read and learn more about that approach by taking DSA2101, or by learning from Wickham, Çetinkaya-Rundel, and Grolemund (2023).
The DataCamp courses cover a little more on R e.g. use of apply family of functions. These will be included in our course, so please pay close attention in the DataCamp course.
If you are coming from a Python background, please remember the following key differences:
$ notation.<-, but in Python it is =.c( ).rep() function to create the following vector: [1] 1 1 1 2 2 3 1 1 1 2 2 3What do the functions saveRDS() and readRDS() do?
From the data2 dataframe in Section 1.5, return all rows where either Gender is equal to “M”, or HW is “A”.
Create a list object that, when printed, returns:
$`1`
$`1`[[1]]
[1] "Will"
$`1`[[2]]
[1] "Mike"
$`1`[[3]]
[1] "Dustin"
$`1`[[4]]
[1] "Lucas"
[[2]]
[1] "Max"&& be used?packages are simply collections of functions.↩︎